
AMD Zen 6 ISA Revealed: What AVX-512 FP16, VNNI INT8, and New Core Layouts Signal for CPUs
The first concrete clues about AMD’s next big CPU step have arrived not through a flashy keynote, but in the quiet, meticulous world of compiler patches. A new GCC entry titled “Add AMD znver6 processor support” surfaces an initial instruction set profile for the upcoming Zen 6 core. While compiler support is not a benchmark and certainly not a product launch, it does outline what software can begin targeting – and that tells us a lot about where Zen 6 is headed.
The patch enumerates a handful of meaningful extensions: AVX512_FP16, AVX_NE_CONVERT, AVX_IFMA, and AVX_VNNI_INT8. In parallel, third-party sleuthing has spotted a fresh CPU ID (B80F00) associated with the Zen 6 generation, likely one of several IDs tied to different families. Put together, these details sketch an architecture that doubles down on mixed-precision math, AI inference efficiency, and broader AVX-512 coverage – areas where developers have been asking for parity across vendors and platforms.
Why these ISA flags matter
AVX-512 FP16 brings native half-precision floating point to AMD’s AVX-512 implementation, cutting data footprint versus FP32 and often boosting throughput for workloads that tolerate lower precision: real-time inference, physics in some games and engines, media effects, emulation, and certain HPC kernels. This isn’t carte blanche performance; devs will still pick precision per algorithm. But FP16 unlocks a well-understood efficiency lever that software ecosystems increasingly exploit.
AVX_VNNI_INT8 (Vector Neural Network Instructions for 8-bit integers) is the other headline. It accelerates the INT8 multiply-accumulate patterns at the heart of modern inferencing, including common transformer and CNN pathways after quantization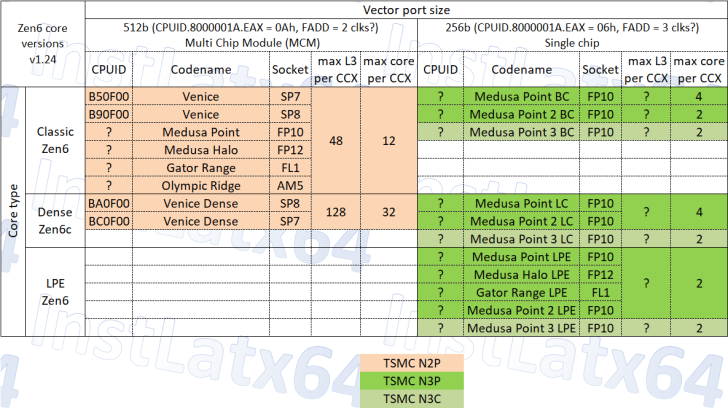
. Combined with AVX_IFMA (integer fused multiply-add) and AVX_NE_CONVERT (handy for vectorized numeric conversions), Zen 6 looks engineered to keep x86 CPUs relevant for the swelling class of edge and client AI tasks where latency trumps sheer throughput.
Server roadmap: Venice classic vs. dense
On the platform side, the Zen 6 server family carries the EPYC “Venice” codename and splits into two variants: Classic and Dense. Today’s identifiers – SP7 “B50F00” and SP8 “B90F00” for Classic, SP7 “BC0F00” and SP8 “BA0F00” for Dense – point to distinct die strategies. Classic is projected to offer up to 12 cores per CCX, while Dense aims as high as 32 cores per CCX. With a platform cap at 256 total cores (i.e., eight CCXs maxed), the dense flavor would carry remarkable cache: 128 MB of L3 per CCX, topping out at a full 1,024 MB across the package. That’s a lot of near-compute memory for highly parallel workloads, from in-memory analytics to microservice consolidation.
Client lineup: Olympic Ridge, Gator Range, and the Medusas
Zen 6 isn’t a server-only story. On the client side, expect at least four families: the high-end AM5 desktop line “Olympic Ridge” with up to 24 cores / 48 threads (12-core CCXs with 48 MB L3 each), plus Gator Range for enthusiast-class mobile and two APU lines: Medusa Point and Medusa Halo. Multi-chip module (MCM) designs are slated to leverage TSMC N2P, while monolithic APUs within Medusa Point and Gator Range are expected on TSMC N3P/N3C. The mix suggests AMD intends to pair compute-dense chiplets with feature-packed monolithic dies where graphics, media, and NPU blocks can shine.
Timing and expectations
Compiler enablement usually precedes hardware by months or more. AMD’s upcoming Financial Analyst Day may drop high-level teases, but substantive Zen 6 announcements are currently tracking to CES 2026. That’s sensible: big desktop and server platforms need long software run-ups and extensive validation. Between now and then, watch the toolchains; when Clang/LLVM and libraries like oneDNN, BLAS variants, or game engines widen support, you’ll know Zen 6-ready binaries are around the corner.
Addressing the loud debates
“Is Zen 6 DOA?” That refrain pops up every generation. Reality: a GCC patch is not a performance chart. It confirms capabilities, not clock targets, power envelopes, or cache latencies. Judging “dead on arrival” before silicon is theater, not analysis.
“AVX-512 doesn’t matter.” It matters when the software uses it. Many consumer apps won’t light up these paths immediately, but virtualization, emulation, media, and AI inference increasingly do. The presence of FP16 and VNNI INT8 reduces the gap between CPU and accelerator for select jobs and simplifies cross-platform code paths.
“Isn’t this just copying Intel’s ISA?” x86 has a long, public history of cross-licensing and shared evolution. Vendors routinely converge on similar extensions because developers demand common primitives. That’s not scandal; it’s ecosystem pragmatism – and why your code compiles cleanly across machines.
“What about Intel’s Nova Lake?” Competition is the point. If Nova Lake lands strong, the market wins with faster iteration, healthier pricing, and better efficiency. Zen 6’s disclosed toolchain targets show AMD is preparing an equally serious response, especially around AI-friendly math.
What to watch as a user or developer
- GCC/Clang flags like
-march=znver6and library releases that annotate Zen 6 paths. - Game engine and emulator patches that toggle FP16/INT8 hot loops.
- Early server SKUs that reveal the actual mix of CCXs and how close real-world cache behavior tracks to the theoretical 1 GB L3 maximum on Dense.
- Mobile/APU disclosures clarifying how NPUs, GPUs, and CPU cores cooperate on common AI workloads.
Zen 6, as revealed by its ISA footprint and family scaffolding, looks like an architecture designed to harmonize classic throughput with the realities of AI-inflected software. It won’t replace accelerators, but it may make your everyday CPU a lot more capable in the tasks you actually run – long before every app ships a dedicated NPU path.
2 comments
AVX-512 FP16 is the sleeper win. Emulators and some render tools are gonna love it. Smaller data, more throughput… yes please
Nova Lake vs Zen 6? I’m here for cheaper CPUs and lower power bills. Let them duke it out, I’ll buy the best perf per dollar lol